Modeller
OpenAI lancerer GPT-5.5
OpenAIs seneste frontier-model – SOTA på de fleste benchmarks, med særlig styrke på kodning, computerbrug og vidensarbejde.

En tidslinje over de begivenheder i moderne AI-historie, der gjorde indtryk og satte spor i udviklingen.

OpenAIs seneste frontier-model – SOTA på de fleste benchmarks, med særlig styrke på kodning, computerbrug og vidensarbejde.
GPT Image 2 er OpenAIs flagskibs billedmodel bag ChatGPT Images 2.0—stærkere verdensviden og prompt-følgning, tæt tekst og layouts, valgfri thinking-tilstand med reasoning og værktøjer (herunder web-underbygning), og konsistente batch-billeder; API-snapshot dateret 21. apr. 2026.
OpenAIåbner i nyt fanebladMoonshot AI udgav Kimi K2.6 som en open-source, kodningsfokuseret model til langvarig kodning, design drevet af kode, agentsværme, proaktive agenter og Claw Groups.
Moonshot AIåbner i nyt fanebladAnthropic gjorde Opus 4.7 generelt tilgængelig med stærkere avanceret software engineering, bedre højopløsnings-vision og forbedret langvarig opgaveudførelse.
Anthropicåbner i nyt fanebladEn SOTA-model til avanceret autonom cybersikkerheds-reasoning, begrænset udgivet af sikkerhedshensyn, sammen med Project Glasswing for at sikre open source-software med store industripartnere.

Z.ai udgav GLM-5.1 som sit næste generations flagship til agentisk engineering med stærkere kodning, langvarig værktøjsbrug og åbne vægte under MIT-licens.
Z.aiåbner i nyt fanebladFrontier-model til professionelt arbejde, udgivet i ChatGPT, API'et og Codex med stærkere ræsonnement, kodning, computerbrug og værktøjsbrug.
OpenAIåbner i nyt fanebladGoogles seneste flagship. Mere end fordobler ræsonneringsydelsen i forhold til Gemini 3 Pro. Udgivet i preview via Gemini API, AI Studio og Vertex AI.
Beta-udgivelse med rapid learning-arkitektur – forbedres ugentligt via brugerfeedback. 256K kontekst, 4-agent parallel ræsonnering. Medicinsk dokumentanalyse tilføjet.
Den hidtil mest kapable Sonnet. Fuld opgradering på tværs af kodning, computerbrug, ræsonnering med lang kontekst, agentplanlægning og design. 1M token kontekstvindue i beta.
Kinas første frontier-model fra et børsnoteret AI-selskab. Sigter mod kompleks systemteknik og langsigtede agentiske opgaver.
Anthropic opgraderede sin stærkeste Opus-model med bedre kodning, længere agentiske opgaver, stærkere code review og debugging samt 1M token kontekst i beta.
Anthropicåbner i nyt fanebladDen mest kapable agentiske kodningsmodel. Ny generation i Codex-linjen til software engineering. Tilgængelig via Codex-app, CLI og IDE-udvidelser.
OpenAI introducerede GPT-5.2 Codex som sin kodningsfokuserede model til agentisk softwareudvikling med stærkere langvarig kodning, review og debugging.
OpenAIåbner i nyt fanebladHurtig frontier-model der måler sig med større modeller til en brøkdel af prisen. Standardmodel i Gemini-appen.
En frontier-modelfamilie til professionelt arbejde og langvarige agenter med Pro-, Thinking- og base-varianter.

Sparse MoE med 41 mia. aktive parametre. Åbne vægte. Stærkt ræsonnement og flersproget.
Åben-vægt-model fra Z.ai i top på globale kodnings- og ræsonnerings-ranglister. Inkluderer varianten GLM-4.7 Flash.
Yderligere iteration af V3-serien. Stærkere på tværs af benchmarks.
Anthropics mest kapable model bragte en oplyst nøjagtighedsforbedring på 20%, Infinite Chats og stærkere Excel- og finansmodelleringsflows.

Googles mest kraftfulde model afløste 2.5-serien og hævdede en forbedring på over 50% i forhold til Gemini 2.5 Pro.

Inkrementel opdatering af Grok 4. Bedre ræsonnement og instruktionsfølgning. Tilgængelig på X og via API.
Fire modeller med adaptivt ræsonnement. Hurtigere, mere samtale, bedre kodning. Rullet ud til alle ChatGPT-brugere.
Opgraderet Kimi-model med tænkning og ræsonnement.
Første GLM-model med indbygget understøttelse af Kinas hjemmeproducerede chips (Cambricon, Moore Threads). FP8- og Int4-kvantisering.
Stor opgradering fra V3. Bedre ræsonnement og kodning. Åbne vægte.
Syn-sprogmodel fra Z.ai. 106 mia. parametre, stærk multimodal forståelse.
Et næste generations flagship med et stort intelligensspring på tværs af kodning, matematik, skrivning og reasoning.

OpenAIs første open-weight modeller siden GPT-2 kom i 20B- og 120B-varianter og markerede et historisk open-source skifte.

Opgradering til Claude 4. Forbedret kodning, instruktionsfølgning og værktøjsbrug.
Nyeste Anthropic-model. Bedre kreativ skrivning, nuancer og flertrins-ræsonnement.
Z.ai flagship-åben MoE. 355B i alt, stærk på ræsonnement, kodning og agenter. Angiveligt billigere at køre end DeepSeek.
Dedikeret kodemodel fra Qwen. 480B MoE med 35 mia. aktive parametre.
xAI's mest kraftfulde model bragte et stort reasoning-spring og blev trænet på en udvidet Colossus-klynge.

En massiv MoE på en billion parametre med åbne vægte, konkurrencedygtig med frontier-modeller og en stor kinesisk AI-milepæl.

OpenAIs mest kraftfulde ræsonneringsmodel. Udvidet tænkning til grænseproblemer.
Nyeste 2.5 Pro. Forbedret kodning, ræsonnement og agentiske evner.
Anthropics stærkeste modelgeneration skubbede parallel værktøjsbrug og lange autonome opgaver frem.

Hurtig efterfølger til 3.7 Sonnet. Fremragende balance mellem hastighed og intelligens.
Omkostningseffektiv ræsonnering. Kontrollerbar tanke-dybde. #1 i Chatbot Arena på hastighed.
Et agentisk kodeværktøj, der kan skrive, teste og rette kode end-to-end, integreret i ChatGPT for Pro, Team og Enterprise, og som lagde fundamentet for Codex i dag.

Topklasse, konkurrencedygtig med GPT-4o. Apache 2.0. Stærk på flere sprog.
Effektiv ræsonneringsmodel. Bedste pris-ydelse til kodning og STEM.
Den fulde o3-ræsonneringsmodel. Efterfølger til o1. Dyb tankekæde.
Optimeret til kodning og instruktionsfølgning. 1M kontekst. 50% billigere end GPT-4o.
Scout og Maverick bragte indbygget multimodalitet, hvor Scout nåede et kontekstvindue på 10 millioner tokens.

Gemini 2.5 Pro kom med indbygget reasoning, en kontekst på en million tokens og førsteplads på LMArena ved lancering.

OpenAI rullede billedgenerering direkte ind i GPT-4o—nyttige, prompt-præcise, fotorealistiske billeder med stærk tekstgengivelse, forfinelse over flere trin i chatten, C2PA-provens og udrulning på ChatGPT-niveauer (API-adgang fulgte kort efter).
OpenAIåbner i nyt faneblad1B/4B/12B/27B. Multimodal (tekst+syn). Én GPU. 128K kontekst.
Tilføjer syn til Small 3.0. Multimodal, 128K kontekst. Apache 2.0.
Dedikeret ræsonneringsmodel fra Qwen-holdet. Stærk på matematik og logik. Apache 2.0.
Et agentisk kodeværktøj i terminalen, der kan læse, ændre, teste og køre på tværs af hele kodebaser, og som lagde fundamentet for Claude Code i dag.

Største OpenAI-model indtil nu. Fokus på EQ, kreativitet og færre hallucinationer.
Hybrid-ræsonnement — skift mellem øjeblikkelig og udvidet tænkning. Bedste kodemodel ved lancering.
Trænet på Colossus-supercomputeren (100K GPU’er). Stærke ræsonnementsegenskaber.
En åben reasoning-model der konkurrerede med o1, bygget omkring en ren RL-tilgang og stærk nok til at sende chokbølger gennem markedet.

En 671B-parameter MoE trænet for angiveligt $5,5 mio. og konkurrencedygtig med GPT-4o og Claude 3.5 Sonnet, hvilket ændrede debatten om omkostningseffektivitet.

Eksperimentel ræsonneringsmodel med synlig tankekæde. Googles svar på o1.
Multimodal output (tekst, billeder, lyd). Bygget til agentisk AI. 2× hurtigere end 1.5 Pro.
Sora 1 satte en ny standard for tekst-til-video med stærk realisme og bevægelse, gav bredere adgang og skærpede kapløbet mellem OpenAI og konkurrenter som Googles Veo inden for generativ video.

Forbedret ræsonneringsmodel med mere compute til svære opgaver. Tilgængelig i ChatGPT Pro.
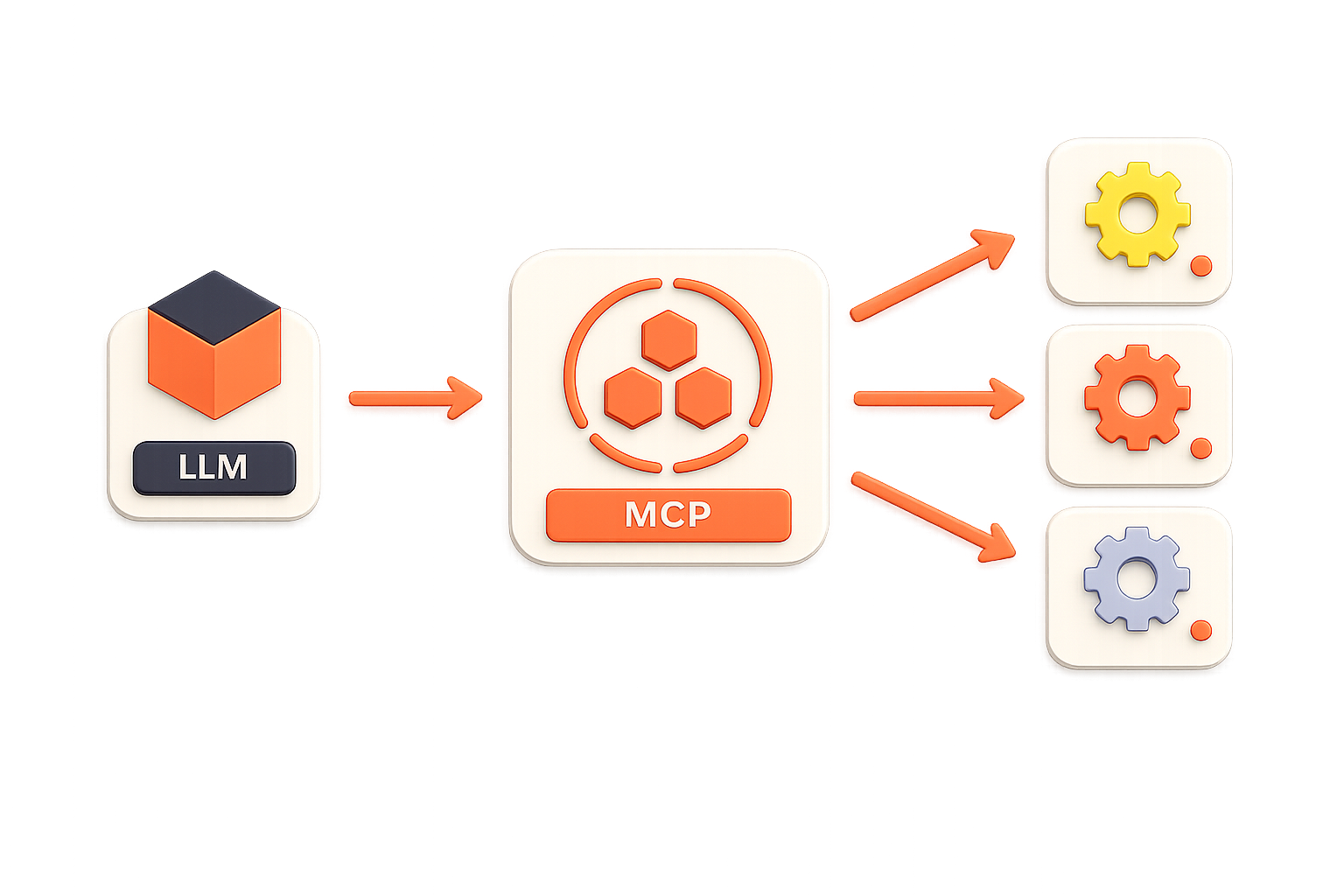
En open-source protokol til at forbinde LLM'er med værktøjer, data og systemer, som standardiserer hvordan modeller får adgang til ekstern kontekst på tværs af AI-økosystemet.
OpenAIs første reasoning-model satte ræsonnement ved inference i centrum og sigtede mod PhD-niveau i naturvidenskab og matematik.

Konkurrencedygtig med GPT-4o og Claude 3.5 og tilgængelig på X-platformen.

128K kontekst. Konkurrencedygtig med GPT-4o og Llama 3.1 405B. 12 sprog.
405B-modellen blev øjeblikkets største åbne model med 128K kontekst og præstationer tæt på GPT-4 på mange benchmarks.

Størrelserne 9B og 27B. Slår modeller der er dobbelt så store. Vidensdestillation fra Gemini.
Claude 3.5 Sonnet overgik GPT-4o og Gemini 1.5 Pro på flere benchmarks og var dobbelt så hurtig som Claude 3 Opus til lavere pris.

Første åbne MoE-kodemodel der matcher GPT-4 Turbo på kodning. 338 programmeringssprog.
Åben GLM-4-serie (bl.a. 9B): 128K kontekst, 26 sprog — på niveau med Llama 3 8B.
En omni-model med indbygget lyd, vision og tekst, som var dobbelt så hurtig og 50% billigere end GPT-4 Turbo.

236B MoE med kun 21 mia. aktive parametre. Multi-head latent attention for bedre effektivitet.
Trænet på 15 billioner tokens og udgivet i 8B- og 70B-størrelser blev LLaMA 3 en ny open-source SOTA med massiv adoption.

Stor MoE med otte eksperter à 22 mia. parametre. Stærk på flere sprog og kode. Åbne vægte.
xAI's første open-source model var en 314B-parameter MoE under Apache 2.0 og en af de største åbne MoE-modeller på tidspunktet.

Haiku, Sonnet og Opus bragte 200K kontekst og vision, hvor Opus matchede GPT-4 på mange benchmarks.

Mistrals første kommercielle flagship-model. 32K kontekst. Ræsonnement i top.
Googles åbne model bygget på Gemini-forskning. Størrelserne 2B og 7B. Meget stærk i sin klasse.
Et kontekstvindue på en million tokens, MoE-arkitektur og behandling af hele kodebaser gjorde den til et stort spring for lang kontekst.

Mest kapable Gemini 1.0. Slog GPT-4 på 30/32 benchmarks. Driver Gemini Advanced.
Åben mixture of experts. Matchede GPT-3.5-kvalitet med kun 12,9 mia. aktive parametre. Et gennembrud.
Googles Gemini-familie kom i Nano-, Pro- og Ultra-størrelser og var designet som multimodal fra træningen.

DALL·E 3 kom i ChatGPT Plus og Enterprise: skab og forfin billeder i chatten med en model der følger lange, detaljerede prompte tættere, med bedre gengivelse af tekst og detaljer og sikkerhedsforanstaltninger før bred udrulning.
OpenAIåbner i nyt fanebladMistral 7B slog Llama 2 70B på flere benchmarks på trods af mindre størrelse, bragte sliding-window attention med og kom under Apache 2.0 — Mistral AIs første åbne model.
En af de første store open-weight modeludgivelser til kommerciel brug, med 7B-, 13B- og 70B-størrelser samt RLHF-tunede chatvarianter.

Claude 2 udvidede Anthropics offentlige modelserie med stærkere evner og bredere adgang via chat- og API-flader.

Claude og Claude Instant blev Anthropics første bredt introducerede assistentmodeller og en direkte ChatGPT-konkurrent.

GPT-4 kunne tage imod både tekst og billeder og hævede barren for frontier-modellers ræsonnement og multimodale evner.

Elon Musk stiftede xAI med den mission at udvikle AI, der fremmer forståelsen af universet.

En meget tidlig version af Cursor lagde AI-native chat, edits og kodebase-reasoning ind i IDE'en; senere voksede det til et af de førende udviklerværktøjer og var med til at kickstarte vibe coding.

LLaMA 1 og de lækkede vægte antændte open-source LLM-bølgen og viste, at små modeller kunne nærme sig GPT-3-niveau.

GPT-3.5 med RLHF i en chatflade nåede 100 millioner brugere på to måneder og kom til at definere den moderne AI-æra.

OpenAI udgav to-trins-systemet bag DALL·E 2: én model skaber CLIP-billed-embeddings ud fra en billedtekst, og en diffusionsbaseret afkoder gør dem til billeder—skarpere, mere fotorealistisk end den første DALL·E.
OpenAIåbner i nyt fanebladViste at mindre modeller trænet på mere data kan slå større undertrænede modeller, og ændrede forståelsen af scaling laws.

Introducerede RLHF til alignment og banede vejen for at træne modeller til sikkert at følge menneskelige instruktioner.

Dario og Daniela Amodei og en gruppe tidligere OpenAI-kolleger (rapporteret som syv medstiftere, blandt andre Jared Kaplan, Jack Clark og Chris Olah) stifter Anthropic som public benefit corporation med sikkerhed i centrum efter strategisk uenighed med OpenAIs kurs ift. tempo og kommercialisering.

En transformer med 12 mia. parametre trænet på tekst–billed-par, der skaber billeder ud fra beskrivelser på almindeligt sprog—kan kombinere begreber, styre udseende og perspektiv og erstatte dele af et billede—et skridt mod at dirigere visuelle idéer med sprog.

OpenAI frigiver GPT-2 men tilbageholder den største version ved lancering af frygt for misbrug. Den decoder-only transformer trænes med next-token prediction til at generere sammenhængende tekst.

OpenAI præsenterer den første Generative Pre-trained Transformer (GPT) og viser stærk NLP-præstation via unsupervised fortræning og supervised finjustering.
OpenAI introducerer Proximal Policy Optimization (PPO)—en enklere og mere stabil policy gradient-metode, der siden blev bredt brugt inden for reinforcement learning, herunder i RLHF.
Google introducerer Transformer-arkitekturen, et gennembrud i dyb læring baseret på attention-mekanismen. Arkitekturen giver store forbedringer på oversættelsesopgaver.
Christiano m.fl. publicerer reinforcement learning from human feedback (RLHF), en teknik der senere blev central til at aligne store sprogmodeller.
Facebook udgiver PyTorch—et dyb lærings-framework bygget omkring Python, der senere blev det dominerende valg i AI-forskning.

DeepMinds AlphaGo slår top-spilleren Lee Sedol i brætspillet Go og viser et niveau, som mange anså for umuligt.
Præsenteret som nonprofit med co-chairs Sam Altman og Elon Musk, CTO Greg Brockman, forskningschef Ilya Sutskever og stiftende forskere blandt andre Andrej Karpathy, John Schulman, Durk Kingma og Wojciech Zaremba—forpligtet til digital intelligens til gavn for menneskeheden og åben udgivelse af resultater.
Google frigiver TensorFlow som open source—deres interne framework til dyb læring, udviklet blandt andet i Google Brain-teamet. TensorFlow blev et af de mest udbredte AI-frameworks.

Demis Hassabis, Shane Legg og Mustafa Suleyman starter DeepMind for at gå efter generel AI via deep reinforcement learning og spil; Google opkøbte labbet i 2014, og i april 2023 fusionerede det med Google Brain som Google DeepMind.