Models
OpenAI launches GPT-5.5
OpenAI's latest frontier model—SOTA on most major benchmarks, with standout strength in agentic coding, computer use, and knowledge work.

A timeline of the biggest events in modern AI history — a running list of what mattered.

OpenAI's latest frontier model—SOTA on most major benchmarks, with standout strength in agentic coding, computer use, and knowledge work.
GPT Image 2 is OpenAI’s flagship image model behind ChatGPT Images 2.0—stronger world knowledge and instruction following, dense text and layouts, optional thinking mode with reasoning and tools (including web-informed generation), and consistent multi-image batches; API snapshot dated Apr 21, 2026.
OpenAIopens in a new tabMoonshot AI published Kimi K2.6 as an open-source coding-focused model for long-horizon coding, coding-driven design, agent swarms, proactive agents, and Claw Groups.
Moonshot AIopens in a new tabAnthropic made Opus 4.7 generally available with stronger advanced software engineering, better high-resolution vision, and improved long-running task performance.
Anthropicopens in a new tabA SOTA model for advanced autonomous cybersecurity reasoning, released restrictively for safety, alongside Project Glasswing to secure open-source software with major industry partners.

Z.ai released GLM-5.1 as its next-generation flagship for agentic engineering, with stronger coding, long-horizon tool use, and open weights under the MIT License.
Z.aiopens in a new tabFrontier model for professional work, released in ChatGPT, the API, and Codex with stronger reasoning, coding, computer use, and tool-use capabilities.
OpenAIopens in a new tabGoogle's latest flagship. More than doubles reasoning performance over Gemini 3 Pro. Released in preview via Gemini API, AI Studio, and Vertex AI.
Beta release with rapid learning architecture — improves weekly via user feedback. 256K context, 4-agent parallel reasoning. Medical document analysis added.
Most capable Sonnet yet. Full upgrade across coding, computer use, long-context reasoning, agent planning, and design. 1M token context window in beta.
China's first public AI company frontier model. Targets complex systems engineering and long-horizon agentic tasks.
Anthropic upgraded its smartest Opus model with stronger coding, longer agentic work, better code review and debugging, and a 1M token context window in beta.
Anthropicopens in a new tabMost capable agentic coding model. Next-generation Codex line for agentic software engineering. Available via Codex app, CLI, and IDE extensions.
OpenAI introduced GPT-5.2 Codex as its coding-focused model for agentic software engineering, with stronger long-running coding, review, and debugging workflows.
OpenAIopens in a new tabFast frontier-class model rivaling larger models at a fraction of the cost. Default model in the Gemini app.
A frontier model family for professional work and long-running agents, including Pro, Thinking, and base variants.

Sparse MoE with 41B active params. Open weights. Strong reasoning and multilingual.
Open-weights model from Z.ai topping global coding and reasoning leaderboards. Includes GLM-4.7 Flash variant.
Further iteration on V3 series. Enhanced capabilities across all benchmarks.
Anthropic's most capable model brought a reported 20% accuracy gain, Infinite Chats, and stronger Excel and financial-modeling workflows.

Google's most powerful model replaced the 2.5 series and claimed a 50%+ improvement over Gemini 2.5 Pro.

Incremental update to Grok 4. Improved reasoning and instruction following. Available on X and via API.
Family of four models with adaptive reasoning. Faster, more conversational, improved coding. Rolled out to all ChatGPT users.
Upgraded Kimi model with thinking and reasoning capabilities.
First GLM model with native support for China's domestic chips (Cambricon, Moore Threads). FP8 and Int4 quantization.
Major upgrade to V3. Improved reasoning and coding. Open weights.
Vision-language model from Z.ai. 106B parameters, strong multimodal understanding.
A next-generation flagship with a major intelligence leap across coding, math, writing, and reasoning.

OpenAI's first open-weight models since GPT-2 arrived in 20B and 120B variants, marking a historic open-source shift.

Upgrade to Claude 4. Improved coding, instruction following, and tool use.
Newest Anthropic model. Improved creative writing, nuance, multi-step reasoning.
Z.ai flagship open MoE. 355B total, strong reasoning, coding, and agentic capabilities. Claimed cheaper to run than DeepSeek.
Dedicated coding model from Qwen. 480B MoE architecture with 35B active parameters.
xAI's most powerful model brought a major reasoning leap and was trained on an expanded Colossus cluster.

A massive one-trillion-parameter MoE with open weights, competitive with frontier models and a major Chinese AI milestone.

Most powerful OpenAI reasoning model. Extended thinking for frontier problems.
Latest 2.5 Pro. Enhanced coding, reasoning, agentic capabilities.
Anthropic's strongest model generation pushed parallel tool use and long autonomous tasks.

Fast successor to 3.7 Sonnet. Excellent speed-intelligence balance.
Cost-efficient reasoning. Controllable thinking depth. #1 Chatbot Arena for speed.
An agentic coding tool that can write, test, and fix code end-to-end, integrated into ChatGPT for Pro, Team, and Enterprise, laying the foundation for today's Codex.

Front-tier, competitive with GPT-4o. Apache 2.0. Strong multilingual.
Efficient reasoning model. Best cost-performance for coding and STEM.
Full o3 reasoning model. Successor to o1. Deep chain-of-thought.
Optimized for coding/instruction following. 1M context. 50% cheaper than GPT-4o.
Scout and Maverick brought native multimodality, with Scout reaching a 10-million-token context window.

Gemini 2.5 Pro launched with built-in reasoning, a one-million-token context window, and the top LMArena position at launch.

OpenAI shipped native image generation inside GPT-4o—useful, prompt-accurate, photorealistic output with strong text rendering, refinement across turns in chat, C2PA provenance, and rollout across ChatGPT tiers (developers gained API access shortly after).
OpenAIopens in a new tab1B/4B/12B/27B. Multimodal (text+vision). Single GPU. 128K context.
Adds vision capabilities to Small 3.0. Multimodal, 128K context. Apache 2.0.
Dedicated reasoning model from Qwen team. Strong mathematical and logical reasoning. Apache 2.0.
An agentic coding tool in the terminal that can read, modify, test, and execute across entire codebases, laying the foundation for today's Claude Code.

Largest OpenAI model yet. Focus on EQ, creativity, reduced hallucinations.
Hybrid reasoning — toggle instant/extended thinking. Best coding model at launch.
Trained on Colossus supercluster (100K GPUs). Strong reasoning capabilities.
An open reasoning model rivaling o1, built around a pure RL approach and strong enough to send shockwaves through the market.

A 671B-parameter MoE trained for a reported $5.5M and competitive with GPT-4o and Claude 3.5 Sonnet, reshaping the cost-efficiency debate.

Experimental reasoning model with visible chain-of-thought. Google's answer to o1.
Multimodal output (text, images, audio). Built for agentic AI. 2x faster than 1.5 Pro.
Sora 1 set a new standard for text-to-video with strong realism and motion, opening broad access and accelerating the race between OpenAI and rivals such as Google’s later Veo in generative video.

Enhanced reasoning model with more compute for complex tasks. Available in ChatGPT Pro tier.
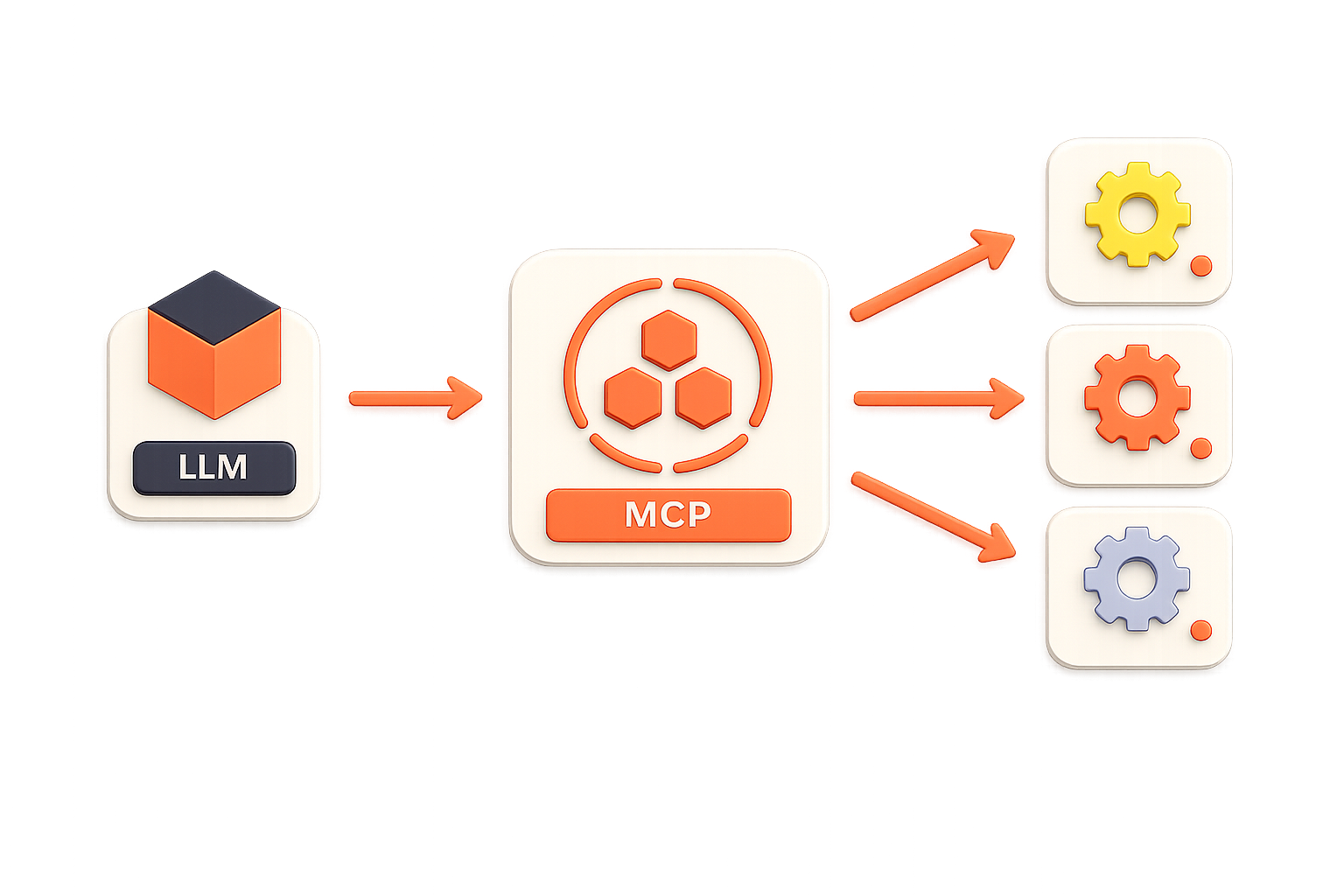
An open-source protocol for connecting LLMs to tools, data, and systems, standardizing how models access external context across the AI ecosystem.
The first OpenAI reasoning model put inference-time reasoning in the spotlight and targeted PhD-level science and math tasks.

Competitive with GPT-4o and Claude 3.5 and available on the X platform.

128K context. Competitive with GPT-4o and Llama 3.1 405B. 12 languages.
The 405B model became the largest open model of its moment, with 128K context and performance near GPT-4 on many benchmarks.

9B and 27B sizes. Outperforms models 2x its size. Knowledge distillation from Gemini.
Claude 3.5 Sonnet surpassed GPT-4o and Gemini 1.5 Pro on several benchmarks while running twice as fast as Claude 3 Opus at lower cost.

First open MoE code model matching GPT-4 Turbo on coding. 338 programming languages.
Open-weight GLM-4 series (incl. 9B): 128K context, 26 languages — competitive with Llama 3 8B.
An omni model with native audio, vision, and text that was twice as fast and 50% cheaper than GPT-4 Turbo.

236B MoE with only 21B active. Multi-head Latent Attention for efficiency.
Trained on 15 trillion tokens and released in 8B and 70B sizes, LLaMA 3 became a new open-source state of the art with massive adoption.

Large MoE with 8 experts of 22B parameters. Strong multilingual and code performance. Open weights.
xAI's first open-source model was a 314B-parameter MoE released under Apache 2.0 and among the largest open MoE models at the time.

Haiku, Sonnet, and Opus brought 200K context and vision, with Opus matching GPT-4 on many benchmarks.

Mistral's first flagship commercial model. 32K context. Top-tier reasoning.
Google's open-source model from Gemini research. 2B and 7B sizes. Strong for its class.
A one-million-token context window, MoE architecture, and whole-codebase processing made it a major leap in long-context modeling.

Most capable Gemini 1.0. Beat GPT-4 on 30/32 benchmarks. Powers Gemini Advanced.
Open-source mixture of experts. Matched GPT-3.5 quality with only 12.9B active params. Game-changer.
Google's Gemini family arrived in Nano, Pro, and Ultra sizes and was designed as natively multimodal from training.

DALL·E 3 shipped in ChatGPT Plus and Enterprise: create and iterate on images in chat, with a model that follows long, detailed prompts more closely, improved rendering of text and fine detail, and responsible-deployment mitigations before broad use.
OpenAIopens in a new tabMistral 7B outperformed Llama 2 70B on common benchmarks despite being much smaller, introduced grouped-query sliding-window attention, and shipped under Apache 2.0 — Mistral AI’s first open-weight release.
One of the first major open-weight model releases for commercial use, with 7B, 13B, and 70B sizes plus RLHF-tuned chat variants.

Claude 2 expanded Anthropic's public model lineup with stronger capabilities and broader access through chat and API surfaces.

Claude and Claude Instant became Anthropic's first broadly introduced assistant models and a direct ChatGPT competitor.

GPT-4 could accept both text and images, raising the bar for frontier-model reasoning and multimodal capabilities.

Elon Musk founded xAI with a mission to develop AI that advances our understanding of the universe.

A very early version of Cursor put AI-native chat, edits, and codebase reasoning inside the IDE; it later grew into one of the leading developer tools and helped kickstart vibe coding.

LLaMA 1 and its leaked weights ignited the open-source LLM wave and showed smaller models could approach GPT-3-class performance.

GPT-3.5 with RLHF in a chat interface reached 100 million users in two months and helped define the modern AI era.

OpenAI published the two-stage system behind DALL·E 2: a model generates CLIP image embeddings from a text caption, and a diffusion decoder turns them into images—sharper, more photoreal results and a big step up from the original DALL·E.
OpenAIopens in a new tabProved that smaller models trained on more data can outperform larger undertrained ones, redefining scaling laws.

Introduced RLHF for alignment and pioneered the technique of training models to follow human instructions safely.

Dario and Daniela Amodei and a group of former OpenAI colleagues (reported as seven co-founders, including Jared Kaplan, Jack Clark, and Chris Olah) form Anthropic as a public benefit corporation, prioritizing safety after strategic tension with OpenAI’s direction on speed and commercialization.

A 12-billion-parameter transformer trained on text–image pairs to synthesize images from natural-language captions—combining disparate concepts, controlling attributes and viewpoint, and inpainting regions—showing that rich visual compositions can be steered with words.

OpenAI releases GPT-2 but withholds the largest version at launch due to misuse concerns. The decoder-only transformer is trained with next-token prediction to generate coherent long-form text.

OpenAI reveals the first Generative Pre-trained Transformer (GPT), demonstrating unsupervised pre-training followed by supervised fine-tuning for strong downstream NLP performance.
OpenAI introduces Proximal Policy Optimization, a simpler and more stable policy gradient method that would become widely used across many reinforcement learning domains, including RLHF.
Google introduces the Transformer architecture, a breakthrough deep learning architecture based on the attention mechanism. The architecture shows strong gains on language translation tasks.
Christiano et al. publish the technique of reinforcement learning from human feedback (RLHF), which would later be used extensively to align large language models.
Facebook releases PyTorch, a Python-first deep learning framework that would eventually become the dominant framework for AI research.

DeepMind's AlphaGo defeats top human player Lee Sedol in the board game Go, defying what many considered possible.
Announced as a nonprofit with co-chairs Sam Altman and Elon Musk, CTO Greg Brockman, research director Ilya Sutskever, and founding researchers including Andrej Karpathy, John Schulman, Durk Kingma, and Wojciech Zaremba—committed to digital intelligence that benefits humanity and broad publication of results.
Google open-sources TensorFlow, its internal deep learning framework. Initially developed by the Google Brain team, TensorFlow would become one of the most influential AI frameworks.

Demis Hassabis, Shane Legg, and Mustafa Suleyman start DeepMind to pursue general AI via deep reinforcement learning and games; Google acquired the lab in 2014, and in April 2023 it merged with Google Brain as Google DeepMind.